
Machine learning models are powerful tools that could help businesses make more informed decisions and optimize their operations. However, as these models are deployed and run in production, they are subject to a phenomenon known as model drift.
Model drift occurs when the performance of a machine learning model degrades over time due to changes in the underlying data, leading to inaccurate predictions and potentially significant consequences for a business. To address this challenge, organizations are turning to MLOps, a set of practices and tools that help manage the lifecycle of production machine learning.
In this article, we'll explore model drift, the different types of it, how to detect it, and most importantly, how to handle it in production using MLOps. By understanding and managing model drift, businesses can ensure that their machine learning models remain accurate and effective over time, delivering the insights and outcomes that they need to thrive.

Photo by Nicolas Peyrol on Unsplash
What is Model Drift?
Model drift, also known as model decay, is a phenomenon in machine learning in which the model performance decreases over time. This means that the model will gradually start to give bad predicitions that will decrease the accuracy over time.
There are different reasons for model shifting such as changes in data collection or the underlying relationships between variables. Therefore the model will fail to catch these changes and the performance will decrease as the changes increase.
Detecting and addressing model drift is one of the essential tasks that MLOps solve. Techniques such as model monitoring are used to detect the presence of model drift and model retraining is one of the main techniques used to overcome model drift.
Types of Drift
Understanding the type of model drift is essential to update the model based on the changes that occurred in the data. There are three main types of drift:
Concept Drift
Concept drift occurs when the relationship between the target and the input changes. Therefore the machine learning algorithm will not provide an accurate prediction. There are four main types of concept drift:
- Sudden Drift: A sudden concept drift occurs if the relationship between the independent and dependent variables occurs suddenly. A very famous example is the sudden occurrence of the covid 19 pandemic. The occurrence of the pandemic has suddenly changed the relationship between the target variable and the features in different fields so a predictive model trained on pre-trained data will not be able to predict during the pandemic time accurately.
- Gradual Drift: In a gradual concept drift, the relation between the input and the target may change slowly and subtly. This can result in a slow decline in the performance of a machine learning model, as the model becomes less accurate over time. An example of the gradual concept drift is fraudulent behavior. Fraudsters tend to understand how the fraud detection system works and change their behavior over time to escape the system. Therefore a machine learning model trained on historical fraudulent transaction data will not accurately predict the gradual changes in the fraudster's behavior. For example, consider a machine learning model used for predicting stock prices in which the model is trained on data from the past five years and its performance is evaluated on new data from the current year. However, as time goes by, the market dynamics may change, and the relationship between the variables that influence stock prices may evolve gradually. This can result in incremental drift, where the model's accuracy gradually deteriorates over time as it becomes less effective at capturing the changing relationship between the variables.
- Incremental Drift: Incremental drift occurs when the relationship between the target variable and the input changes gradually over time which occurs usually due to changes in the data generating process.
- Recurring Drift: This is also known as seasonality. A typical example is the increase in sales during Christmas or Black Friday. A machine learning model that will not inaccurate these seasonal changes into account will end up providing inaccurate predictions for these seasonal changes.
These four types of concept drift are shown in the figure below.
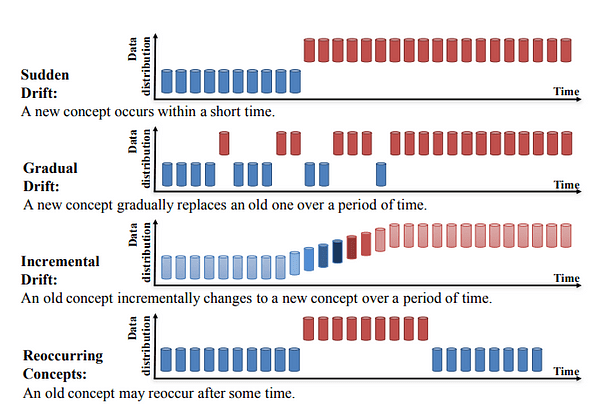
Types of concept drift | Image from Learning under Concept Drift: A Review.
Data Drift
Data drift occurs when the statistical properties of the input data change. An example of this is the change in the age distribution of the user of a certain application over time, therefore a model trained on a specific age distribution that is used for marketing strategies will have to be changed as the change in the age will affect the marketing strategies.
Upstream Data Changes
The third type of drift is the upstream data changes. This refers to the operational data changes in the data pipeline. A typical example of this is when a specific feature is no longer generated resulting in a missing value. Another example is a change in the unit of measurement for example if a certain sensor measure quantity in Celsius and then changes into Fahrenheit.
Detecting Model Drift
Detecting model drift is not straightforward and there is no universal method to detect it. However, we will discuss some of the popular methods to detect it:
- The Kolmogorov-Smirnov test (K-S test): The K-S test is a nonparametric test to detect the change in the data distribution. It is used to compare the training data and the post-training data and find the distribution changes between them. The null hypothesis for this test set states that the distribution from the two datasets is the same so if the null hypothesis is rejected, therefore there will be a model shift.
- The Population Stability Index (PSI): PSI is a statistical measure that is used to measure the similarity in the distribution of categorical variables in two different datasets. Therefore it can be used to measure the changes in the characteristics of categorical variables in the training and post-training dataset.
- Page-Hinkley Method: The Page-Hinkely is also a statistical method that is used to observe changes in the mean of data over time. It is usually used to detect the small changes in the mean that is not apparent when looking at the data.
- Performance Monitoring: One of the most important methods to detect the concept shift is monitoring the performance of the machine learning model in production and observing its change and if it crosses a certain threshold we can trigger a certain action to correct this concept shift.
Handling Drift in Production 
Handling Drift in Production | Image by ijeab on Freepik.
Finally, let's see how to handle the detected model drift in production. There is a wide spectrum of strategies used to handle the model drift depending on the type of drift, the data we are working on, and the project in production. Here is a summary of the popular methods that are used to handle model drift in production:
- Online Learning: Since most of the real-world applications run on streaming data, online learning is one of the common methods that are used to handle the drift. In online learning the model is updated on the fly as the model deal with one sample at a time.
- Periodically Model Re-train: Once the model performance falls below a certain threshold or a data shift is observed a trigger can be set to retrain the model with recent data.
- Periodically Re-train on a Representative Subsample: A more effective way to handle concept drift is by selecting a representative subsample of the population and labeling them using human experts and retraining the model on them.
- Feature Dropping: This is a simple but effective method that can be used to handle concept drift. Using this method we will train multiple models each using one feature and for each model, the AUC-ROC response is then monitored, and if the value of the AUC-ROC went beyond a certain threshold using a particular feature then we can drop it as this might participate in drifting.
References
- Best Practices for Dealing With Concept Drift
- Understanding Data Drift and Model Drift: Drift Detection in Python
- Machine Learning Concept Drift?—?What is it and Five Steps to Deal With it
In this article, we discussed model drift, which is the phenomenon in machine learning where the performance of a model deteriorates over time due to changes in underlying data. Businesses are turning to MLOps, a set of practices and tools that manage the lifecycle of machine learning models in production, to overcome these challenges.
We outlined the different types of drift that can occur, including concept drift, data drift, and upstream data changes, and how to detect model drift using methods such as the Kolmogorov-Smirnov test, Population Stability Index, and Page-Hinkley method. Finally, we discussed the popular techniques to handle model drift in production including online learning, periodic model re-train, periodically re-train on a representative subsample, and feature dropping.
Youssef Rafaat is a computer vision researcher & data scientist. His research focuses on developing real-time computer vision algorithms for healthcare applications. He also worked as a data scientist for more than 3 years in the marketing, finance, and healthcare domain.
- Detecting Data Drift for Ensuring Production ML Model Quality Using Eurybia
- How to Detect and Overcome Model Drift in MLOps
- Production Machine Learning Monitoring: Outliers, Drift, Explainers &…
- How to break a model in 20 days — a tutorial on production model analytics
- Model Drift in Machine Learning — How To Handle It In Big Data
- MLOps: Model Monitoring 101