
When AMD launched MI300X at its Advancing AI event, during the presentation Lisa Su, the CEO of AMD, and her colleagues showcased the accelerator’s prowess by comparing it with NVIDIA H100’s inference performance using Llama 2. At the presentation, a single server of AMD which consists of eight MI300X, performs 1.6 times faster than the server of an H100.
But NVIDIA wasn’t happy with the comparison and debunked it. According to a blog post by NVIDIA, contrary to AMD’s presentation, the company contended that the H100 GPU, when benchmarked appropriately with optimised software, outpaces the MI300X by a substantial margin.
NVIDIA countered this by alleging that AMD failed to incorporate its optimisations in the comparison with TensorRT-LLM. NVIDIA’s response involved pitting a single H100 against eight-way H100 GPUs while running the Llama 2 70B chat model.
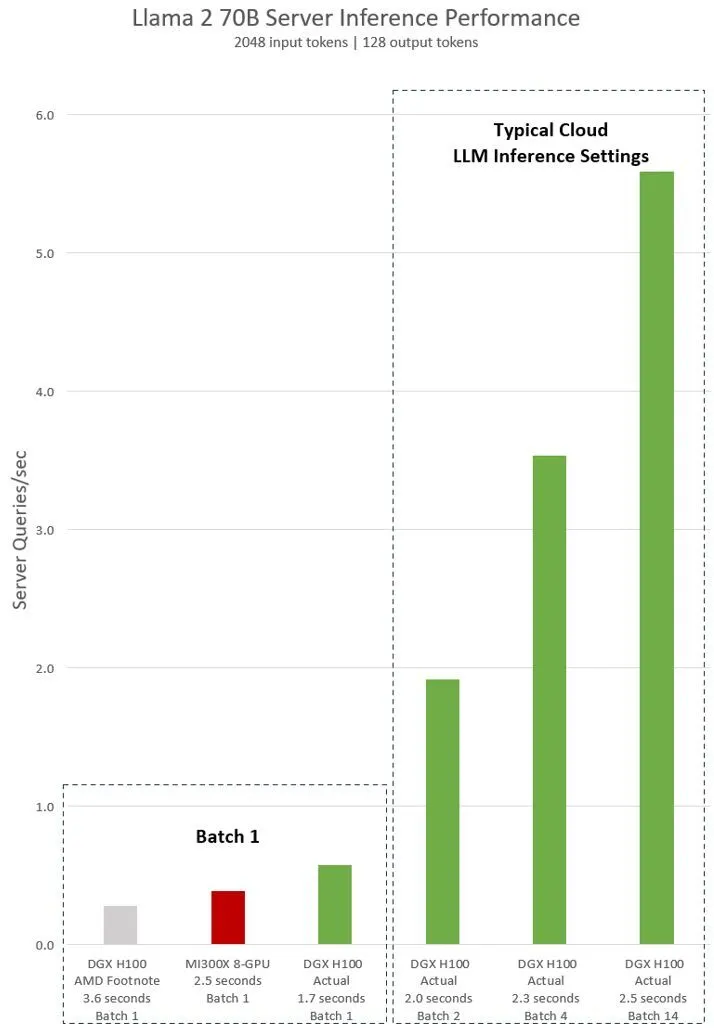
The results, obtained using software predating AMD’s presentation, demonstrated a performance that was twice as fast at a batch size of 1. Going even further, when applying the standard 2.5-second latency used by AMD, NVIDIA emerges as the undisputed leader, surpassing the MI300 by an astonishing 14-fold.
AMD snaps back
Surprisingly, AMD responded to NVIDIA’s challenge with new MI300X benchmarks, demonstrating a 30% increase in performance compared to the H100, even with a finely-tuned software stack.
In a move mirroring NVIDIA’s test conditions with TensorRT-LLM, AMD took a proactive approach, considering latency, a common factor in server workloads. AMD emphasised key points in its argument, particularly highlighting the advantages of FP16 using vLLM over FP8, which is exclusive to TensorRT-LLM.

AMD asserted that NVIDIA conducted benchmarks with its proprietary TensorRT-LLM on H100 instead of the widely-used vLLM.
Additionally, AMD points out the discrepancy in data type usage, with NVIDIA employing vLLM FP16 on AMD while comparing it to DGX-H100’s TensorRT-LLM with FP8 datatype. AMD defends its choice of vLLM with FP16, citing its broad usage, unlike vLLM, which lacks support for FP8.
Another point of contention is the consideration of latency in server environments. AMD criticises NVIDIA for focusing solely on throughput performance without addressing real-world latency issues.
To counter NVIDIA’s testing method, AMD conducted three performance runs using NVIDIA’s TensorRT-LLM, with the final run specifically measuring latency between MI300X and vLLM using the FP16 dataset against H100 with TensorRT-LLM.
The tests showcased improved performance and reduced latency. AMD applied additional optimisations, resulting in a 2.1x performance boost compared to H100 while running vLLM on both platforms.
Meanwhile, competitions galore
NVIDIA and AMD’s competition has been going on for a long while. But interestingly, this is the first time that NVIDIA decided to directly compare its products’ performance against AMD. This clearly shows that the competition in the field is heating up.
Currently, the ball is in NVIDIA’s court to formulate a response to AMD, considering the implications of abandoning FP16 in favour of TensorRT-LLM’s closed system with FP8, while also keeping in mind that others such as Intel and Cerebras are getting better at making GPUs.
Not just the two chip giants, others such as Cerebras Systems and Intel are also trying to make their mark in the market. Pat Gelsinger, the CEO of Intel, teased the Gaudi3 AI chip at its AI Everywhere event, though there was very little revealed about it. Comparatively, the other products released by Intel such as Core Ultra were being compared to the last generation of AMD’s, not the latest one.
Similarly, NVIDIA is coming up with GH200 superchips, a successor to the H100, early next year. AMD did not compare its new chips with it, but with H100. It is clear that GH200 would obviously perform better than the last ones. Since the competition is so close, AMD might end up being treated like a backup option by many companies, such as Microsoft, Meta, and Oracle, who have already announced they are integrating it in their data centres.
Gelsinger has projected that the GPU market size would be around $400 billion by 2027. This definitely gives room for a lot of competitions to thrive.
Meanwhile, Cerebras Systems’ CEO Andrew Feldman, at the Global AI Conclave, took a shot at NVIDIA’s monopolistic practices. “We spend our time figuring out how to be better than NVIDIA,” he said. “By next year, we will build 36 exaflops of AI compute power,” he added about the company’s ambitious plans.
Cerebras Systems’ CEO is also in talks with the government of India for powering AI compute in the country. The company also signed a $100 million AI supercomputer deal with G42, an AI startup in UAE, where NVIDIA isn’t allowed to work.
The post GPU Battle: NVIDIA vs AMD appeared first on Analytics India Magazine.